Lucid-XR: An Extended-Reality Data Engine for Robotic Manipulation
Paper Video Demo Code (Coming Soon)
We build an intuitive VR data collection interface entirely in simulation for imitation learning. We demonstrate an amplification and learning pipeline to produce learn visual policies from purely synthetic data that generalize to real-world scenes. Our system plugs into any SoA imitation learning method, amplifying data collection capacity 20x.
Lucid-XR enables intuitive end-effector control by using gaze-activated mocap sites, allowing natural grasp gestures even at a distance.
Abstract
We introduce Lucid-XR, a generative data engine for creating diverse and realistic multi-modal data to train real-world robotic systems. At the core of Lucid-XR is vuer, a web-based physics simulation environment that runs directly on the XR headset, enabling internet-scale access to immersive, latency-free virtual interactions without requiring specialized equipment. The complete system integrates on-device physics simulation with human-to-robot pose retargeting. The data collected is further amplified by a physics-guided video generation pipeline steerable via natural language specifications. We demonstrate zero-shot transfer of robot visual policies to unseen, cluttered, and poorly lit evaluation environments, after training entirely on Lucid-XR's synthetic data. We include examples across dexterous manipulation tasks that involve soft materials, loosely bound particles, and rigid body contact.
On-Device Data Collection
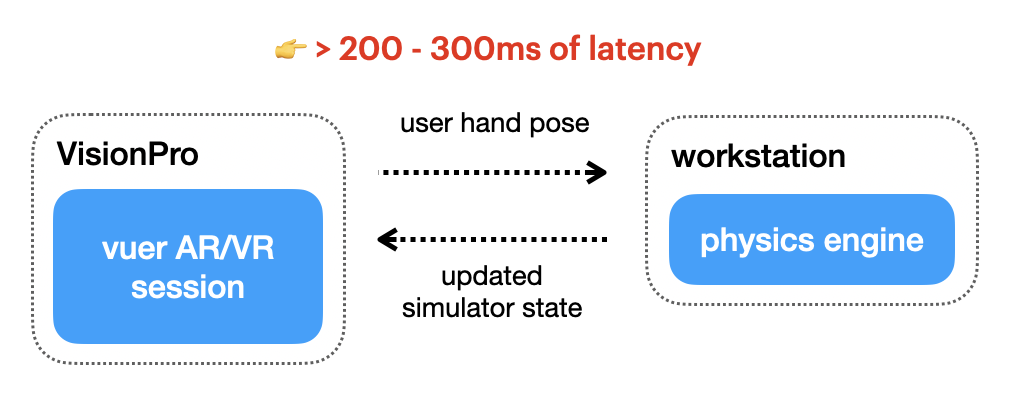
Existing VR Setup
Lucid-XR 🎥
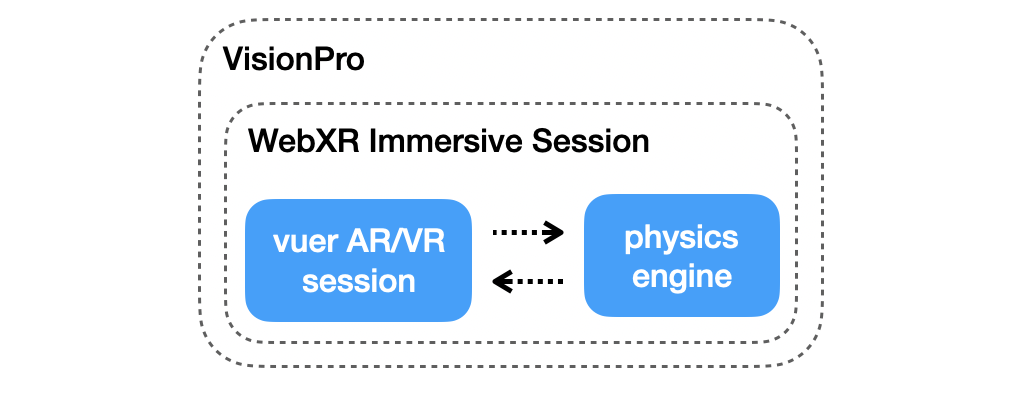
Lucid-XR ▶ enables scalable data collection. We build upon three web-standards WebXR, WebGL, and Web Assembly to enable on-device MuJoCo-based physics simulation running at the device's native speed. An interactive demo of vuer is below. The manipulation tasks contain interactive grippers with interactive mocap points.
Large scenes, fast dynamics, and flexible objects are some of many physics types LucidXR can simulate on-device.
Task Gallery
We trained a variety of visual imitation-learning policies in simulation on versatile tasks. For select tasks, we applied the augmentation methods below to train policies on synthetic imagery and evaluate them in realistic 3D Gaussian Splatting-based environments. Those policies have never seen the MuJoCo or the 3DGS visuals before.
Mug Tree
Precise Insertion & SDF

Ball Toy
Long Horizon
Microwave Muffin
Articulated Objects

Pour Liquid
Particles & Dexterous Hands

Drawer Stowing
Articulated Objects
Tie Knot
Flexible Objects

Basketball
Precise Dynamics
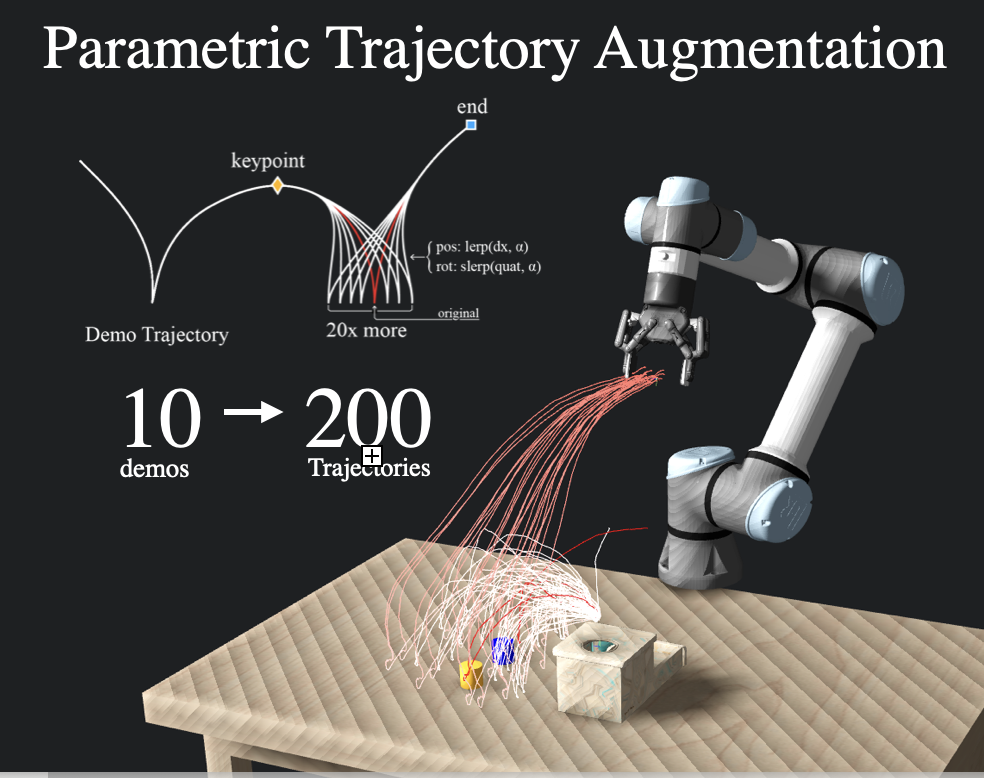
Synthesizing Diverse Manipulation Data
Synthetic data allows for easy data augmentation by warping and moving programatically-labelled keypoints in the trajectory within the training distribution. Using LERP and SLERP we can multiply our data by 10x, limited only by computational constraints.
The collected trajectories are visually amplified through our geometry-guided video-generation pipeline, steered via natural language. Policies trained on this have only ever seen the right-most images. This allows robot generalization to unseen environments and the real-world.
RGB
Depth
Lucid-XR
Deploying Across Embodiments
The data collected with Lucid-XR is embodiment-free. The observation and action spaces for all of our policies are the end-effector state. These policies can be deployed zero-shot across different embodiments limited only by inverse kinematics solvers.
Citation
@inproceedings{
ravan2025lucidxr,
title={Lucid-{XR}: An Extended-Reality Data Engine for Robotic Manipulation},
author={Yajvan Ravan and Adam Rashid and Alan Yu and Kai McClennen and Gio Huh and Kevin Yang and Zhutian Yang and Qinxi Yu and Xiaolong Wang and Phillip Isola and Ge Yang},
booktitle={9th Annual Conference on Robot Learning},
year={2025},
url={https://openreview.net/forum?id=3p7rTnLJM8}
}